Open Source
Production Ready
Zero Config
2Free Projects Forever
Trusted by developers who ship fast
Star us on GitHubRushDB turns any JSON or CSV into graph
RushDB, a high-performance graph database, built on top of Neo4j,
intelligently maps relationships, types, and labels any input data, so you don’t have to.
Smart Auto-Normalization
From a single JSON payload 4 normalized Records with automatic Relationships
COMPANY
DEPARTMENT
PROJECT
EMPLOYEE
RushDB automatically creates Records with proper relationships and types from your JSON.
Zero schemas, maximum speed — built for SaaS, AI apps, and fast-moving teams.
32MB
In a single payload or...
10 000+ products for online store
100 000+ financial transactions
1 000 000+ API logs
~0.25ms
Batch write speed per Record
Transactions (ACID)
Ensures data integrity and reliability
Push JSON. Query JSON.
If you can push JSON, why not query with JSON too?
Simple, consistent, developer-friendly — no SQL, no complexity.
JSON inJSON out
Simple Syntax for Complex Queries
RushDB’s graph database engine and APIs make it easy to ask real questions — without writing verbose logic or managing queries manually.
Clean JSON responses every time
Structured JSON responses with clear data shapes. No (de)normalization headaches, just clean results ready for your app.
Smart Faceted Search Out of the Box
RushDB's property graph design means every filter makes your search smarter. The more you filter, the more precise your options become — like marketplace category filters that automatically reduce brand choices, but for any dataset at any scale.
Properties are managed autonomously by RushDB — search capabilities are delivered instantly at record creation time. No manual indexing, no configuration — just intelligent faceted search that works out of the box.
Property Graph Topology
Relationships That Make Sense
Connect your data naturally. It's like foreign keys but without the mental overhead —
control relationships the way you actually think about them.
Beyond Firebase Limitations
Firebase forces you into document hierarchies. Supabase and ORMs make you overthink schemas and joins.
RushDB's graph architecture connects data instantly. No complex joins, no rigid schemas — just natural relationships that scale.
USER
MANAGES
PROJECT
Live Demo: See RushDB in Action
Experience the power of RushDB firsthand.
Explore ExamplesLive Preview
db.ts
api.ts
Records.tsx
Use Cases
SaaS & Apps
Power your development with a scalable graph database. RushDB is a Firebase alternative, Supabase alternative, and cloud database built for modern NoSQL needs. It offers high-speed data ingestion,native graph storage, and an unbeatable developer experience — ideal for data-intensive apps and teams seeking a developer-friendly database.
AI & Machine Learning
Building NLP pipelines and Graph RAG was never simpler. RushDB serves as your AI persistence layer — perfect for predictive analytics, AI embeddings, recommendation systems, and vector search. With low-latency and vector database capabilities powered by a knowledge graph engine, it's optimized for AI-first applications and works as a plug-and-play backend as a service.
Persistence for AI Era: Smart and Simple
RushDB handles the complexity – so you can focus on building. Just push JSON, query granularly via JavaScript SDK, Python SDK, or REST API, and let automatic labeling and type suggestions do the rest. Ideal for cloud-first use cases, AI integrations, and GenAI projects.
IoT Projects
Don’t let infrastructure complexity slow down your IoT innovation. RushDB is a scalable database that handles real-time data ingestion, time-series database workloads, and dynamic schemas – making it a go-to NoSQL database for connected devices.
Search Engines
RushDB enables fast, flexible filtering of massive datasets — perfect for building custom search engines using a vector database with knowledge graph support. Optimized for performance and shape-agnostic queries.
Hobby Projects
Don’t let infra kill your weekend flow. RushDB gives you an open source database with zero config, making it perfect for developer-friendly hacking. Push data, build ideas fast, and ship in hours — not weeks.
Create a project, grab your API token,
and start building in less than 15 seconds.
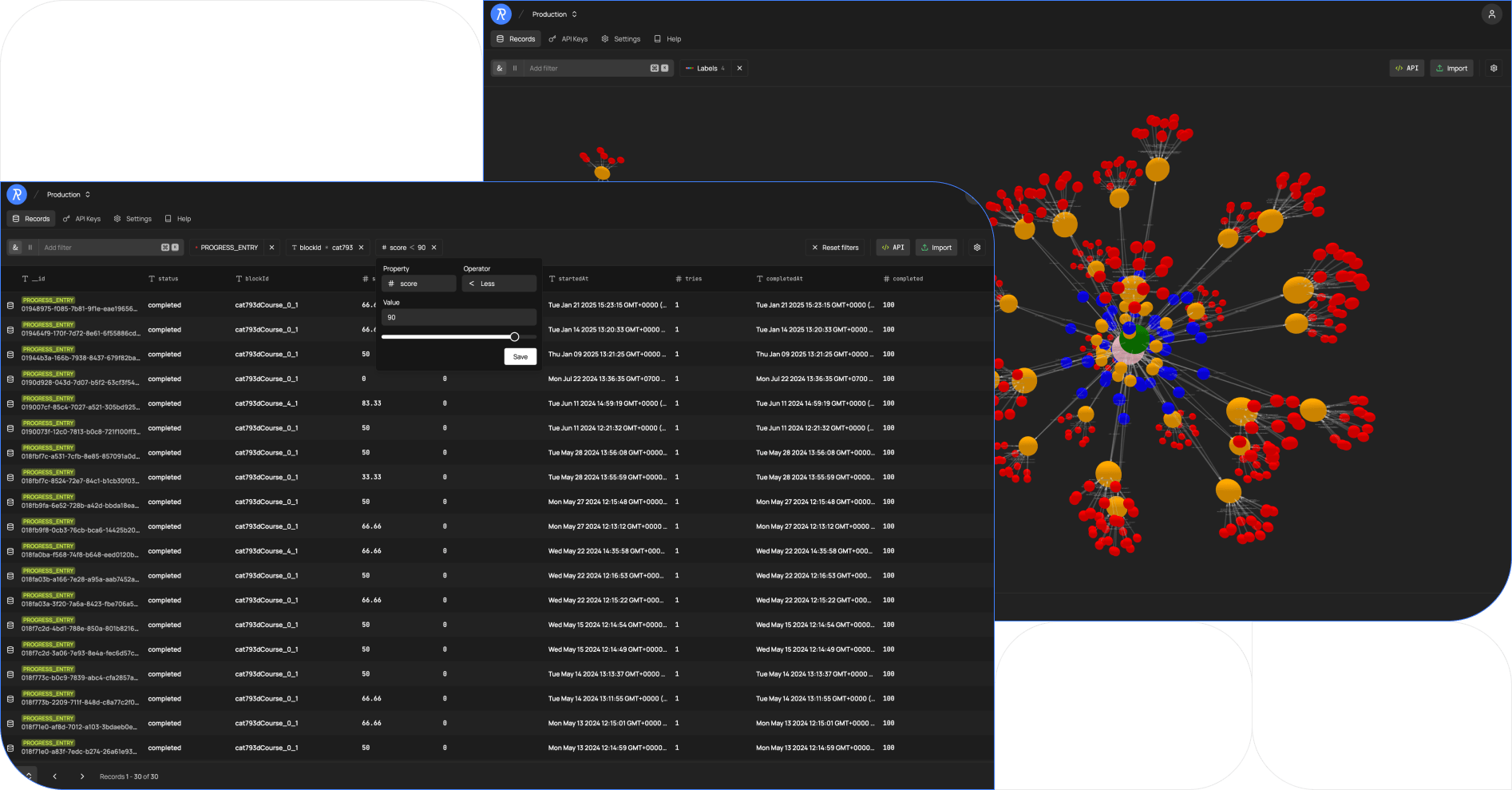
Fully Featured Dashboard
Navigate your data quickly and clearly with an interface designed for speed and clarity.
Bring your own Neo4j instance
Scale your high-demand workloads with full data ownership.
Self-hosted? Simple.
1. Setup your Neo4j instance or use Neo4j Aura
2. Run RushDB container with Neo4j credentials
That's it. RushDB is ready at
localhost:3000 🎉️
Not an infra fan?
Try RushDB Cloud
2 Projects Free Forever. No Maintenance Required.
Focus on building apps, not on managing infrastructure.

Labeled Meta Property Graphs (LMPG): A Property-Centric Approach to Graph Database Architecture
7th July 202534 min read
rushdbgraphsgraph theory
Backendless Fullstack Development: React useForm + RushDB
26th June 20257 min read
tutorialtypesriptfullstack
Introducing RushDB: Zero-Config Instant Database for Modern Apps & AI Era
17th February 202512 min read
databasegraph databaseNoSQL
* Yes, RushDB's blog is built with RushDB 🤓
FAQ
How is RushDB different from Firebase or Supabase?
Unlike Firebase's document hierarchies or Supabase's rigid schemas, RushDB offers a zero-config graph database that automatically normalizes your data. You can push JSON directly without planning your data structure in advance, and query across relationships naturally without complex joins.
Can I use RushDB for AI applications and LLM outputs?
Absolutely! RushDB is designed for the AI era with seamless JSON storage for LLM outputs, automatic relationship detection, and graph-based querying that's perfect for RAG applications, embeddings storage, and knowledge graphs. Our auto-normalization feature is particularly valuable for handling the varied structures of AI-generated content.
How much data preparation do I need before using RushDB?
Zero. RushDB's core value is eliminating data preparation overhead. Just push your JSON or CSV as-is, and RushDB automatically normalizes, connects, and indexes your data with proper relationships and types. This means you can start building features immediately instead of planning database schemas.
What's the performance like for real-world applications?
RushDB processes data at ~0.25ms per record with ACID transaction support, handling payloads up to 32MB. It can manage 10,000+ e-commerce products, 100,000+ financial transactions, or 1,000,000+ API logs in a single operation, making it production-ready for demanding applications.
Can I self-host RushDB or do I have to use the cloud version?
Both options are available. You can self-host using our Docker container with your Neo4j instance, or use RushDB Cloud which offers 2 free projects forever with no maintenance required. For teams that want to focus on building rather than infrastructure, our cloud option eliminates all database management concerns.
Team & Mission


We're two engineers with 15+ years of combined experience at Yandex, 3Commas, and Sumsub. Throughout our careers, we've seen how data management consistently holds teams back - from complex feature additions to database operations and search functionality. Every project required meticulous data planning, normalization, and custom retrieval solutions, creating unnecessary friction and delays.
RushDB exists to eliminate these barriers. Our mission is to make developers unstoppable by radically simplifying data operations. We're building the foundation that lets engineering teams move at maximum velocity - no more wrestling with databases, search implementations, or data restructuring. Just pure, frictionless development focused on shipping features and scaling ideas.
Developer experience is our north star. We believe great software shouldn't be bottlenecked by data infrastructure. By handling the complex data layer, we free developers to focus on what truly matters: creating exceptional products that deliver real value.